클러스터(또는 노드) 재시작하기 - Rolling Restarts
참고 : https://www.elastic.co/guide/en/elasticsearch/guide/current/_rolling_restarts.html
참고 : http://asuraiv.blogspot.kr/2015/04/elasticsearch-rolling-restarts.html
Elasticsearch 클러스터를 운영하다보면, Elasticsearch의 자체의 업그레이드 작업이든, 하드웨어의 교체/업그레이드 작업이든, Elasticsearch 클러스터 전체를 재구동해야하는 경우가 무조건 온다.
이때, 보통 우리가 생각 하듯이 그냥 클러스터 전체를 껐다 키면 되지 않을까? 라는건 조금 저렴한(?) 발상이다. 어쨌든, 각 노드를 하나씩 재구동한다고 했을때, 어떻게 해야할까?
이제부터 'Rolling Restarts'라는 방식을 설명하겠다.
아래와 같은 클러스터 구조가 있다고 하자.
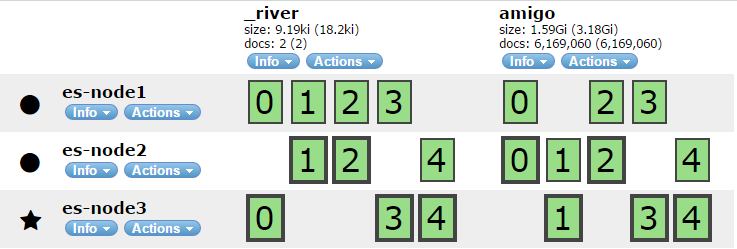
'amigo' 인덱스를 보면,
노드가 3개, Primary Shard가 5개 Replica Shard가 5개인 구조이다. (굵은 테두리로 되어있는 shard가 Primary Shard 이다) 이때, 'es-node1'을 shutdown 한다고 치자. 그렇게 되면 'amigo' 인덱스의 node1에 있는 0,2,3 replica shard는 어떻게 될까?
있을 곳을 잃어버린 위의 3개 shard는 '무작위로' 나머지 node2, node3으로 '재배치'(Reallocation)가 된다. 이때 발생하는것은 고 비용의 IO 작업 이다.
그건 그렇다 치자, 해야하는 작업을 마치고 다시 node1을 구동한다. 원래있던 0,2,3 replica shard가 다시 node1로 돌아가게 될까?
아니다. node2와 node3에 있던 shard들이 무작위로 node1로 옮겨가게되는데, 이때 Elasticsearch는 적절히 각 노드의 균형을 맞춰 shard를 재배치 한다. 이때 발생하는 Rebalance 작업 또한 비용이 상당하다.
게다가 각 shard에 대용량의 데이터가 저장되어있다고 했을때, 이러한 Reallocation, Rebalance 작업은 엄청난 시간이 걸린다 (필자는 노드 하나를 껐다 키고 모든 샤드가 파란색이 될때까지 2시간 이상을 기다린 경험도 있다..)
여기서 필요한게 바로 'Rolling Restarts' 기법이다.
2. Rolling Restarts Steps
이제 각 단계를 살펴보자.
1) 위 그림과 같은 초기 상태이다

가능하면, document가 색인되는것을 중지한다.
2) 아래와 같은 요청으로 shard allocation 옵션을 disable한다
$ curl -XPUT 'localhost:9200/_cluster/settings?pretty=true' -d { "transient" : { "cluster.routing.allocation.enable" : "none" } }이게 Rolling Restarts 의 핵심이다. 이게 왜 핵심인지는 step을 밟아가며 알아보자.
3) 노드를 shutdown 한다. <----- es5.5에서는 _shutdown 명령어가 _shutdown API has been removed
(https://www.elastic.co/guide/en/elasticsearch/reference/5.5/cluster-nodes-shutdown.html)
$ curl -XPOST 'localhost:9200/_cluster/nodes/_local/_shutdown'자, 2)번에서 allocation을 disable 했다. 이러한 설정상태에서 node를 shutdown하면, 아래와같이 shutdown한 node에 있던 shard들은 재배치 되지 않고 'Unassinged' 상태로 남아있다.

바로 위에 언급했던 '불필요한 I/O작업'을 피할 수 있는것이다.
4) 해야하는 작업을 한다 (유지보수/upgrade)
5) node를 다시 구동하고, 클러스터에 합류하는지 확인한다.
$ sudo service elasticsearch start Starting Elasticsearch... Waiting for Elasticsearch...... running: PID:25374

6) 2번에서 disable했던 allocation 옵션을 다시 enable한다.
$ curl -XPUT 'localhost:9200/_cluster/settings?pretty=true' -d { "transient" : { "cluster.routing.allocation.enable" : "all" } }
자 이렇게 되면 'Unassigned' 상태에있던 shard들이 아래와 같이 재배치 될것이다.

하지만 서론에서 언급한것처럼 무작위로 재배치되어 균형을 맞추는것이 아니라, 원래 node1에 있던 shard들, 즉 'Unassigned' 상태에있던 shard 들만 node1로 옮겨간다.
원래 node1에 있던 shard들이 제자리로 돌아 가는 것이니, Rebalance 작업이 필요없는 것이다!
아래와같이 빠른속도로 재배치가 완료된다.

7) 클러스터가 안정화되면(green 상태) 2번~6번 까지의 작업을 다른 node에 반복한다.
3. 결론
'Rolling Restarts'의 핵심은 shard가 allocation되는것을 disable하는것이다. 간단하지 않은가? 이런 설정을 한뒤에 재구동을 하면, 불필요한 I/O작업과 Rebalance 작업을 하지 않아도 되니, 비용절약과 동시에 재구동후의 빠른 클러스터의 안정을 가져다 준다.
Elasticsearch 운영시에 꼭 알아둬야할 기법인 것같다.
'ElasticSearch > 외부자료' 카테고리의 다른 글
| [외부] ELASTICSEARCH – 2. SHARD & REPLICA (0) | 2018.04.20 |
|---|---|
| [외부] Elasticsearch 인덱싱 최적화 (0) | 2018.04.17 |
| [외부] Elasticsearch Configuration (0) | 2018.04.13 |
| [외부] ElasticSearch: Enable Mlockall in CentOS 7 (0) | 2018.04.13 |
| [외부] Elasticsearch로 로그 수집하기, 실전! (0) | 2018.04.12 |