ELASTICSEARCH – 2. SHARD & REPLICA
- Hosang Jeon
- 2014년 2월 23일
- 17820 Views
- 2
- 37 Comments

Elasticsearch의 shard와 replica에 대해서 알아보기 전에, Elasticsearch에서의 노드 생성 및 동작원리에 대해서 간단히 알아보도록 하겠습니다.
사용자가 하나의 머신에서 Elasicsearch를 시작하게 되면, 하나의 Elasticsearch 노드가 생성되며, 이 노드는 동일한 네트워크 상에서 같은 클러스터명을 같는 클러스터가 존재하는 지를 찾게 됩니다 [Figure 1]. 만약, 연결(join)될 수 있는 클러스터가 없다면 이 노드는 스스로 클러스터를 생성하게 되고, 만약 클러스터가 존재한다면 해당 클러스터에 연결됩니다. (Elasticsearch의 클러스터 구성 및 설정에 대해서는 추후에 포스팅 하도록 하겠습니다.)
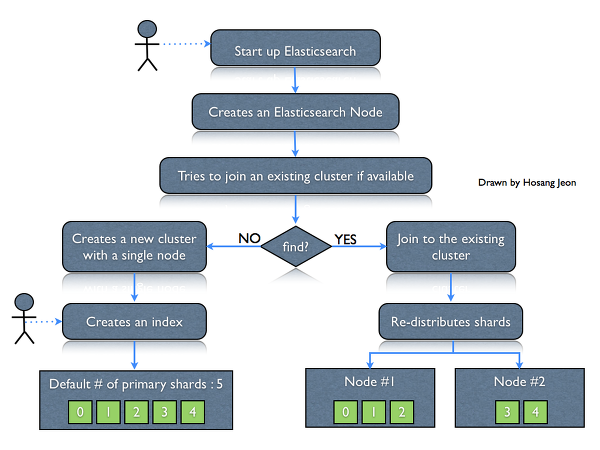
새로운 클러스터가 생성되었다면, 노드에는 아직 어떠한 인덱스도 존재하지 않는 상태이며, 새로운 인덱스를 생성할 때 인덱스를 몇 개의 shard로 나누어 저장할 것인지를 정의할 수 있습니다. Shard의 개수를 따로 지정하지 않는다면, Elasticsearch의 기본 shard 개수인 5개로 데이터가 나누어져 저장됩니다. 만약, 노드가 기존에 존재하던 클러스터에 연결되고 해당 클러스터에 이미 인덱스가 존재한다면 해당 인덱스 shard들은 추가된 노드에 균일하게 재분산 됩니다.
그렇다면 Shard란 무엇일까요?
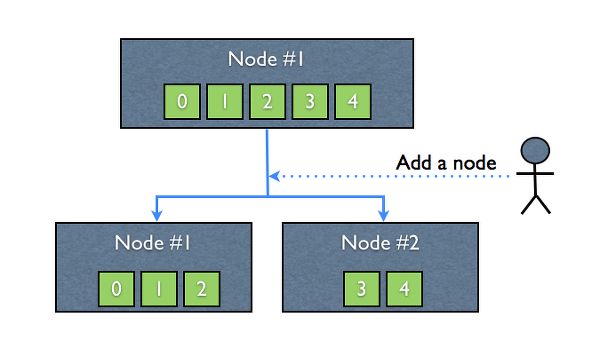
Elasticsearch를 비롯한 많은 수의 분산 데이터베이스(분산 검색엔진)에서 shard란 일종의 파티션과 같은 의미이며, 데이터를 저장할 때 나누어진 하나의 조각에 대한 단위입니다. 여기에서 주의할 점은 각각의 shard는 데이터에 대한 복사본이 아니라, 데이터 그 자체라는 점입니다. shard가 노드에 저장되어 있는 상태에서 아래의 Figure 2.와 같이 하나의 노드가 추가 된다면, 기존에 존재하던 shards는 각 노드에 균일하게 재분산 됩니다. 이렇게 가장 먼저 1copy씩 존재하는 데이터 shard를 primary shard라고 합니다.
그렇다면 이렇게 데이터를 나누어 shard 형태로 저장하는 이유는 무엇일까요?
Elasticsearch는 분산 데이터베이스(분산 검색엔진)이기 때문에, 이렇게 데이터를 나누어 저장하는 방식으로 대용량 데이터에 대한 분산처리를 가능하게 합니다. Primary shard는 각 인덱스 별로 최소 1개 이상 존재해야만 합니다. Shard가 많아지면 그만큼 데이터양의 증가에 대한 Elasticsearch 노드의 확장으로 대응이 가능하다는 장점이 있습니다. 하지만, shard 그 자체도 일종의 비용이라고 할 수 있기 때문에 데이터양의 증가 예측치를 이용하여 적절한 수의 shard를 결정하는 것이 중요합니다.
Elasticsearch에서 Replica는 무엇을 의미할까요?
Replica는 한 마디로 정의하자면 또 다른 형태의 shard라고 할 수 있습니다. Elasticsearch에서 replica의 기본값은 1입니다. 이 때, replica의 값이 1이라는 것은 primary shard가 1개라는 것을 의미하지 않고, primary shard와 동일한 복제본이 1개 있다는 것을 의미합니다. 즉, replica의 개수는 primary shard를 제외한 복제본의 개수 입니다.
Replica가 필요한 이유는 크게 두 가지인데, 그 중 첫 번째는 ‘검색성능(search performance)‘이고, 두 번째는 ‘장애복구(fail-over)‘입니다.
Replica shard는 아래와 같은 중요한 특징을 갖고 있습니다.
Replica shard는 절대로 동일한 데이터를 갖고 있는 primary shard와 같은 Elasticsearch 노드상에 존재할 수 없습니다.
아래의 Figure 3.을 예로 들어 설명하면, 첫 번째 노드의 0, 1, 2번 shard는 primary shard이고, 4, 5번 shard는 replica shard가 됩니다. 마찬가지로 두 번째 노드의 4, 5번 shard는 primary shard이고 1, 2, 3번 노드는 각각 replica shard입니다.
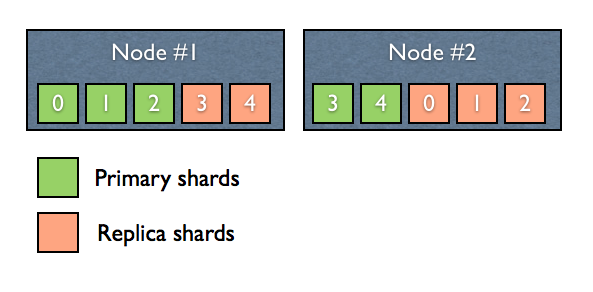
이러한 상황에서 하나의 노드에 문제가 발생하게 된다고 하여도 나머지 노드에 모든 데이터 shrad들이 존재하기 때문에 정상적인 서비스가 가능하며, 문제가 없는 노드에 있던 replica shard가 자동적으로 primary shard가 됩니다. 여기에서 우리는 아래와 같은 계산식을 유추할 수 있습니다.
n개의 노드에서 장애가 발생하였을 때, 서비스가 정상적으로 동작하기 위해서는 최소 n+1개의 노드가 동일 클러스터내에 존재해야 하며, replica의 수는 최소 n개여야만 합니다.
다시 말하자면, 1개의 노드에서 장애가 발생하였을 때, 서비스가 정상적으로 동작하기 위해서는 최소 2개의 노드가 동일 클러스터내에 존재해야 하며, replica의 수는 최소 1개여야만 합니다.
또한, replica의 최대 개수는 전체 노드의 수 -1 입니다. 그러므로, 클러스터상의 노드에 문제가 발생하여 가용한 노드의 수가 replica의 수보다 같거나 작은경우 어떠한 노드에서 할당(assign)되지 못한 shard가 발생하게 되며, 이러한 경우 클러스터의 상태가 “YELLOW“가 됩니다. (정상적인 경우의 클러스터 상태는 “GREEN“)
만약, 문제가 발생하였던 노드가 다시 정상적으로 동작하게 되면 해당 노드는 클러스터상에 연결되고, 할당되지 못하고 남아있던 replica shard들이 해당 노드에 할당됩니다.
좀 더 알아보기
검색의 핵심 개념과 엘라스틱서치의 기본에 대해서 좀 더 자세히 알아보고자 한다면 제가 쓴 책 <스타트업 인 액션>을 참고하시기 바랍니다.
- Categories: Data-side, Elasticsearch
- Tags: cluster, Elasticsearch, NoSQL, Shard
{kind=link}
ABOUT THE AUTHOR
Hosang Jeon
Passionate, responsible and committed engineer, with experiences of designing, implementing and adapting technically sophisticated online web applications.
RELATED POSTS

Elasticsearch Korean Analyzer
- 2015년 5월 5일
MeCab 한글 형태소 분석기 플러그인 설치하기
- 2015년 5월 5일
Elasticsearch – Startup 프로세스 코드리뷰
- 2014년 9월 24일

Elasticsearch 한글 형태소 분석기(Analyzer) 비교
- 2015년 5월 17일
PREVIOUS POSTELASTICSEARCH – 1. 시작하기
37 COMMENTS
- seojeong2014년 3월 13일 at 2:46 오후 - Reply
안녕하세요. 항상 글 잘 보고 있습니다 ^^;
최근 엘라스틱서치에 대해 공부 중 인데, 몇 가지 여쭤보고 싶은게 있어서요.
솔라 클라우드의 경우엔, 리더가 모든 일을 처리하고, 레플리카는 리더가 다운된 경우 선출되어 일을 하는 방식으로 분산을 지원한다는데, 엘라스틱 서치에서는 어떻게 되는지 궁금합니다 ㅜ_ㅜ. 분산 인덱싱과 분산 검색을 어떻게 지원해 주나요?
1) 마스터노드 라는게 있던데, master-slave구조로 마스터가 인덱싱을 하고, 나머지 노드들은 마스터의 인덱스를 복사해서 검색만 하는건가요?
2) 아니면 각각이 document를 받아서 인덱싱하고, 모두 검색을 해주는 방식인건지… 샤딩을 하는 거 보면..그럼 마스터 노드의 역할은 무엇인가요?
3) 둘 다 아니면 어떤 방식인가요..?바쁘시겠지만 부디 답변 부탁드립니다. ㅠㅠ!
안녕하세요.
조금 늦었지만 말씀하신 내용에 대해서 답변을 달아드립니다. ^^
1) 먼저, 마스터 노드는 해당 클러스터에 어떤 노드들이 연결되어 있고, 각 샤드들이 어떤 노드에 위치해 있는지에 대한 정보를 담고 있는 노드입니다. 하나의 인덱스는 (기본적으로) 여러개의 샤드들로 구성되어 있으며, 이 샤드들은 클러스터 상의 노드들에 골고루 분산되어 저장됩니다. 정리하자면, 엘라스틱서치에서 마스터-슬레이브는 클러스터와 이 클러스터에 연결된 노드들을 관리하기 위한 개념이며, 인덱싱과 검색에는 크게 영향을 미치는 개념이 아니라고 생각하시면 됩니다.
2) 먼저, 엘라스틱서치에서 문서가 인덱싱되는 방식을 설명드리겠습니다. 문서에 대한 인덱싱 요청은 먼저 하나의 노드에 전송되는데요, 이 노드는 마스터노드일 수도 있고, 그렇지 않아도 무방합니다. 일반적으로 데이터를 저장하지 않고, 마스터 노드도 아닌 클라이언트 노드(node.master :false node.data:false) 를 두어서 운영하는 경우가 많습니다.
인덱싱 요청을 받은 노드는 문서의 ID 값을 해싱하여 이 문서가 어느 샤드에 저장되어야 하는지를 결정합니다. 만약, 해당 인덱스를 구성하는 샤드의 개수가 5라면, ID의 해시 값은 다섯 개의 범위 중 하나에 포함되게 됩니다. 이런식으로 최초 인덱싱 요청을 받은 노드가 각 문서를 다른 노드(샤드)에 분산시키게 됩니다.검색의 경우 최초 요청을 받은 노드는 해당 검색 요청을 인덱스의 모든 샤드들에 전달하게 되며, 각 샤드들로 부터 받은 검색결과를 취합, 정렬 하여 애플리케이션에 반환합니다. 이 때 검색은 특정 샤드에 대하여 수행되는 것이 아니고, 전체 샤드에 모두 전달되는 것이기 때문에 요청을 받는 노드가 마스터 노드인지 아닌지는 의미가 없다고 보시면 됩니다.
결론적으로 말씀드리자면, 엘라스틱서치에서 마스터 노드는 클러스터와 이를 구성하는 노드 정보를 담고있을 뿐, 검색과 인덱싱에 중요한 역할을 하는 것이 아니기 때문에 요청이 반드시 마스터 노드에 전달되어야 한다거나 하는 등의 제약사항은 없습니다.
3) 위의 내용이 답을 포함하고 있는 것 같습니다.
답변이 도움이 되셨다면 좋겠습니다. ^^
- seojeong2014년 3월 14일 at 5:16 오전 - Reply
그..럼 정말 죄송하지만 ㅠㅠ…제가 가상머신 2개를 띄워놓고, 클러스터에 각각의 노드를 연결을 해보고 싶은데, 자꾸 에러가 떠서요..클러스터에 노드를 연결했을 때, 샤드가 분할되는걸 보고 싶어서요 ㅠㅠ
각각의 elasticsearch.yml 인데, 혹시 조언해주실 수 있으신가요?
192.168.102.133:9200는 다음과 같고cluster.name: singer
node.name: “idol1″
node.master: true
node.data: true
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.multicast.unicasy.hosts: [“192.168.203.133:9200″, “192.168.203.134:9200″]아래는 192.168.102.134:9200 입니다.
cluster.name: singer
node.name: “idol2″
node.master: false
node.data: true
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.multicast.unicasy.hosts: [“192.168.203.134:9200″,”192.168.203.133:9200″]안녕하세요. 출장을 다녀오느라 답변이 좀 늦었습니다. ^^
가상머신에서 Elasticsearch 클러스터를 구성하려면 multicast discovery를 비활성화 시키고 unicast 방식을 이용하는 것이 맞습니다.
그래서 입력하신 설정에는 문제가 없는 것 같습니다.그러나 설정 내용 중에 discovery.zen.ping.multicast.unicasy.hosts 가 아니라, discovery.zen.ping.unicast.hosts 가 맞는 값이라서 이 부분이 문제가 되었을 수 있을 것 같습니다.
만약, 이렇게 바꾸어도 안된다면 호스트 목록의 포트들을 9200이 아닌 9300으로 한번 해보시기 바랍니다. unicast discovery는 tranport 모듈을 사용하기 때문입니다.그리고, 샤드가 분할 되는 것을 눈으로 직접 확인하실 때는 {elasticsearch home}/bin/plugin -install mobz/elasticsearch-head 명령어를 통해 head 플러그인을 설치하시고, 웹브라우저를 통해 http://master_node_ip:9200/_plugin/head/ 로 접속하시면 직관적으로 확인 하실 수 있습니다.
마지막으로, public ip를 통해 외부에서 접근이 필요하신 경우에는 설정파일에서 network.publish_host 의 값을 해당 public ip로 입력해 주시면 됩니다.
감사합니다. ^^
- seojeong2014년 3월 17일 at 2:34 오전 - Reply
unicasy는 제가 옮겨쓰는 도중 오타가 났었어요 ^^;;;
계속 에러 검색하다가 보니 방화벽 문제였네요 ㅠ_ㅠㅋㅋ덕분에 4일을 삽질 ㅠㅠㅠ
도와주셔서 정말정말 감사합니다! 앞으로도 좋은 게시글 부탁드립니다! 좋은하루 되세요!0! 안녕하세요 현재 ES사용중인 유저입니다.
현재 클러스터 구성중인데 글을 읽다고 궁금한점이 있어 글을 남깁니다.
많은 가이드라인에서 client node 즉(node.master :false node.data:false)를 앞에 두고 그뒤로 마스터노드와 데이터노드를 둬서 클라이언트 노드로 통신이 간후 다시 취합하여 사용하기를 권장하는데 여기서 장점은 노드에 많은 요청이안가 부하가 적게걸린다는점인데
클라이언트에 많은요청이가면 이 노드에서는 부하가 안걸리는지가 궁금합니다.
또한 클라이언트노드를 사용하지않고 즉 1개의 마스터노드와 2개의 데이터노드로 사용시 검색을 할때 어느 노드 아이피로 검색을 날려야하는지 궁금합니다. ES홈페이지에는 요청순서는 나와있는데 요청을 받아서 모든 shard에게 요청을 전달하여 결과를 다시 취합하여 사용자에게 전달이라고 나와있는데 이때 요청을 받은 노드로 통신을 한다는 뜻이 특정 노드로만 요청을 해야하는건가요? 아님 클러스터로 구성되어 있어서 클러스터 내 모든 노드들한테 요청이 가는지 궁금합니다.
마지막으로 클라이언트 노드 사용시 요청순서가 궁금합니다.
클라이언트 노드에서 request를 받으면 연결된 모든 노드안의 shard에게 전달하는 방식인가요?안녕하세요. ^^
질문 감사드립니다.먼저, 엘라스틱서치에서는 특별한 경우를 제외하고는 검색 요청이 인덱스를 구성하고 있는 모든 샤드들에 전달되고 각 샤드들로부터 받은 결과를 최초 요청을 받은 노드가 취합 및 정렬등의 작업을 수행한 뒤 최종 결과를 애플리케이션에 전달하게 됩니다. 여기에서 특별한 경우란 커스텀 라우팅을 이용하여 조회(retrieve)하고자 하는 샤드를 지정하는 경우입니다.
만약, 클라이언트 노드를 따로 두지 않는다면 요청을 받은 노드는 자신이 가지고 있는 샤드에 대하여 검색을 수행함은 물론, 다른 샤드들로 부터 받은 결과를 취합하여 반환하는 작업을 수행해야 하기 때문에 혼자서 너무 많은 작업을 수행하게 됩니다.
이러한 이유로, 가지고 있는 샤드에 대하여 검색을 수행하는 데이터 노드와, 검색은 수행하지 않고 요청을 전달하고 결과를 취합하는 역할만 하는 클라이언트 노드를 별도로 두는 것입니다.
물론, 많은 요청이 발생하면 클라이언트 노드에 부하가 집중되겠지만, 이것은 클라이언트 노드를 두지 않는 방법으로 해결하는 것이 아니라, 여러대의 클라이언트 노드를 두고 그 앞에 로드밸런싱을 수행하는 노드를 구성하는 것이 바람직합니다.마지막으로, 클라이언트를 두지 않고, 1개의 마스터 노드와 2개의 데이터노드를 운용한다고 하시면 어떤 노드에 요청을 보내시더라도 성능은 동일하게 되며, 다만, 특정 노드에 요청이 집중되지 않도록 관리해주시면 될 것 같습니다.
만족스러운 답변이 되었는지 잘 모르겠습니다만, 혹시 또 궁금하신 내용이 있으시면 언제든지 댓글 달아주시면 감사하겠습니다. ^^
답변 감사합니다.
한가지 질문이 더 있는데요
ES에서 split brain문제에 대해서 minimum_master_nodes를 n/2+1개로 지정하라고 하는데
제가 현재 총 3개의 노드로 클러스터를 구성할려고하는데 하나는 클라이언트 노드(master:false,data:false) ,데이터 노드(master:false,data:true), 마스터노드(master:true,data:false)로 구성할려고하는데 이경우 최소 마스터노드갯수를 2로 지정하면 문제가 생기는거같습니다. 마스터노드는 하나고 만약을 마스터노드가 죽으면 누가 마스터노드를 살리는 역할을 하나요?
설정은 다음과 같습니다.
master
cluster.name: elasticsearch
node.name: node_data
node.master: true
node.data: false
index.number_of_shards: 5
index.number_of_replicas: 1
network.host:마스터노드아이피
transport.tcp.port: 9300
transport.tcp.compress: true
http.enabled: false
discovery.zen.ping.multicast.enabled: false
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.timeout: 3s
discovery.zen.ping.unicast.hosts: [“마스터노드아이피:9300″, “데이터노드아이피:9300″,”클라이언트노드아이피:9300″]
action.auto_create_index: true
action.disable_shutdown: true
disable_delete_all_indices: true
index.mapper.dynamic: truedata
cluster.name: elasticsearch
node.name: node_data
node.master: false
node.data: true
index.number_of_shards: 5
index.number_of_replicas: 1
network.host: 데이터노드아이피
transport.tcp.port: 9300
transport.tcp.compress: true
http.enabled: false
discovery.zen.ping.multicast.enabled: false
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.timeout: 3s
discovery.zen.ping.unicast.hosts: [“마스터노드아이피:9300″, “데이터노드아이피:9300″,”클라이언트노드아이피:9300″]
action.auto_create_index: true
action.disable_shutdown: true
disable_delete_all_indices: true
index.mapper.dynamic: trueclient
cluster.name: elasticsearch
node.name: node_data
node.master: false
node.data: true
index.number_of_shards: 5
index.number_of_replicas: 1
network.host: 데이터노드아이피
transport.tcp.port: 9300
transport.tcp.compress: true
http.port: 9200
discovery.zen.ping.multicast.enabled: false
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.timeout: 3s
discovery.zen.ping.unicast.hosts: [“마스터노드아이피:9300″, “데이터노드아이피:9300″,”클라이언트노드아이피:9300″]
action.auto_create_index: true
action.disable_shutdown: true
disable_delete_all_indices: true
index.mapper.dynamic: true위설정으로 실행을하면 마스터노드와 데이터노드는 실행되지만 클라이언트노드 실행시
waited for 30s and no initial state was set by the discovery
이와같은 문제가 발생합니다.다시 실행해보니 실행이되지만 마스터노드를 셧다운 시키면 마스터노드가 없어지기때문에 데이터노드가 아무역할을 할수가 없는거같습니다. 데이터 노드쪽에 master :true로 해놓아야하나요?
안녕하세요. JU님.
먼저, 간단히 몇 가지를 설명드리면 좋을 것 같습니다.
1. node.master: true 설정은 해당 노드를 마스터 노드로 선택하겠다는 의미라기 보다, 해당 노드가 마스터 노드가 “될 수도 있게 한다”라는 의미 입니다. 그렇기 때문에 마스터 노드를 한 대와 데이터 노드 한 대를 운영하시기 위해서 하나의 노드는 node.master: true, 다른 하나의 노드는 node.master: false로 지정하실 필요가 없습니다. 다시 말해서 클라이언트 노드를 제외한 두 개의 노드 모두 node.master: true, node.data: true로 설정하시면 클러스터의 master election 과정을 통해 자동으로 하나는 마스터 노드가 되고 다른 하나는 데이터 노드가 됩니다. 이 때, 마스터 노드에 장애가 발생하면 데이터 노드로 사용되던 노드가 마스터가 사라졌음을 인식하고 자신이 마스터로 선출될 수 있는 기회를 얻게 되는 것입니다.
2. Split brain 이슈를 막기 위해서 discovery.zen.minimum_master_nodes 설정의 값을 (N/2)+1 로 권장한다고 할 때, N은 정확히 말하자면 “클러스터를 구성하는 총 노드의 개수”가 아니고, “클러스터를 구성하는 노드들 중, 마스터로 선출될 수 있는(node.master: true) 노드의 개수” 입니다. 즉, 현재 JU님께서 말씀하신 구성(클라이언트노드 1, 마스터가능 노드1, 마스터불가능 노드1)이라고 하면 N 값은 1이 됩니다.
결론적으로 말씀드리자면, 클라이언트 노드의 설정은 그대로 두시고, 나머지 두 개의 노드 설정을 node.master: true, node.data: true로 동일하게 하신 뒤에, 두 노드 중에 어떤 노드를 마스터로 사용할지는 엘라스티서치 자체의 마스터 election 에 맡기셔야 합니다. 인덱싱이나 검색 요청은 어떤 노드가 마스터로 선출되었는지와 상관없이 클라이언트 노드에 요청하시면 되고요. ^^
이렇게 설정을 변경하신 뒤에 discovery.zen.minimum_master_nodes 설정 값을 (2/2)+1 = 2로 설정하시면 마스터 노드를 선정하기 위해 최소 두 개의 노드가 서로 communication 해야 하기 때문에 두 노드간의 통신이 단절되었을 때 마스터 노드가 두 개 선정되는 split brain 문제를 막을 수 있습니다. 다만, 말씀하신 경우에 하나의 마스터 노드에 장애가 발생하면 다른 노드가 discovery.zen.minimum_master_nodes 제한에 따라 마스터로 선정될 수 없기 때문에 전체 클러스터가 사용 불가능 상태가 될 수 있습니다. 이러한 이유로 node.master: true 노드가 두 개일 때에는 발생가능성이 적은 split brain 문제 때문에 minimum_master_nodes 값을 2로 설정하는 것 보다, 가용성을 보장하기 위해서 1로 설정하는 것이 더 좋지 않을까 하는 개인적인 생각입니다. 이 부분에 대해서는 제가 정확히 확신할 수 없어서 다른 내용들을 좀 더 참고해 보시는 것이 좋을 것 같습니다.
감사합니다. ^^
답변감사합니다.
마스터 1 데이터 1 클라이언트1 이렇게 구성하고 discovery.zen.minimum_master_node를 2로 설정하였을 경우 위에서 말씀하신것처럼 마스터 노드에 장애가 발생시 최소 2개의 노드가 통신해야한다는 설정을 위와같이 했기때문에 데이터노드 하나만 남아서 문제가 split brain은 피할수 있지만 남아있는 데이터 노드가 마스터노드로 선정될수없어서 클러스터전체에 장애가 생긴다고 말씀하셨는데 그럼 구성을 마스터1 데이터2 클라이언트1로 구성하고 discovery.zen.minimum_master_node를 2설정시 이문제를 해결할수있겠네요?클라이언트노드를 웹어플리케이션 서버에 붙임 클라이언트 노드를 위해 서버를안만들어도 되어서 가용한 서버가 하나 늘어서 그렇게 구성하면 되지 않을까 싶은데요 제가 이해한게 맞나요?
네. 마스터로 선출될 수 있는 노드(master eligible)가 3개라면 discovery.zen.minimum_master_node 값이 2로 설정되어 있어도 하나의 노드에 장애가 발생하여도 다른 노드가 마스터로 재선출 될 수 있습니다.
클라이언트 노드를 WAS 와 같은 서버에서 운영하시면 하나의 서버가 남기는 하지만 WAS 자체 성능의 저하를 유발하지는 않을지 잘 고민하셔야 할 것 같습니다. 여기에 대해서는 애플리케이션의 트래픽이 어느정도고 동시접속이 어느정도인지 등이 영향을 미치기 때문에 정답은 없고 상황에 맞게 설정하셔야 할 것 같습니다.
그러나 개인적으로는 총 세대의 노드를 하나의 클라이언트노드(node.master:false, node.data:false) 와 두 개의 데이터 노드(node.master:true, node.data:true) 로 사용하시고, discovery.zen.minimum_master_node 값을 1로 설정하시는 편이 좋지 않을까 생각됩니다. split brain 문제는 마스터 노드가 실제로 장애가 없음에도 불구하고 다른 노드와 통신이 불가능하여 발생하기 때문에 그렇게 흔하게 발생하는 케이스는 아니기 때문입니다.
물론, 정답은 없기 때문에 운영해보시면서 최적의 설정을 찾아나가시면 좋을 것 같습니다. ^^
참고로, 클러스터 설정시에 성능 등을 최적화하는 몇 가지 팁을 아래의 링크에서 참고해 보시는 것도 좋을 것 같습니다.
https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/
- 엘라스틱했어요~2015년 2월 2일 at 10:25 오전 - Reply
안녕하세요
좋은 정보 공유로 인해 많은 도움을 받고 있습니다.
한가지 궁금한게 있어 문의 드리는데요….
제가 이번에 클러스터를 두개의 데이터 노드로 구성하여 검색 성능 측정을 하려다 보니…(replica :1, shards :5 로 셋팅)
primary shard에 대해 궁금점이 생겨서요.
1. 저는 처음에 primary shard가 실제로 검색시 검색 결과를 반환하는 shard로 알고 있었는데 그게 맞는지? 아니라면
실제로 primary shard의 정확한 동작 및 의미는 무엇인가요?2. 두대의 데이터 노드 중 1대의 데이터 노드를 먼저 start한 후 나머지 1대의 데이터 노드를 start하면 replica는 각각 1개씩 분배되어
각 노드당 5개의 shard를 가지게 되는데 primary shard는 먼저 start한 노드에만 구성이 되어 있습니다. 이렇게 되면 노드를 2개를
띄워도 성능 향상에 도움이 되지 않는게 아닌가요?(1번 질문의 첫번째 답이 Yes인 경우로 생각 했습니다.)3. primary shard와 master node와는 전혀 관계가 없는 것이 맞는가요? 즉 master node는 실제 검색 시 어떤 노드로 검색 요청을 보내는 지에 대한 meta 정보를 가지고 있을 뿐이고 primary shard는 ….(잘모르겠네요 이게 어떤 역활인지)
조금 두서없이 질문드린것 같아 죄송합니다.ㅠ.ㅠ 답변 부탁드릴게요
안녕하세요. ^^ 댓글 남겨주셔서 감사합니다. ^^
1. 먼저, primary shard 뿐만 아니라, replica shard 도 검색시에 결과를 반환하는 shard 입니다. primary shard 와 replica shard 는 검색시에는 동일하게 동작합니다. ^^ 하지만 indexing 시에는 replica shard 보다 primary shard 가 먼저 인덱싱되는 차이점이 있습니다. http://www.slideshare.net/hosangjeon10/introduction-to-elasticsearch-42781557 이 링크에서 24번째 슬라이드를 보시면 조금 더 잘 이해가 되실 것 같습니다. ^^
2. 말씀하신대로 1번 질문의 답이 No 이기 때문에 성능향상에 도움이 되는 것이 맞습니다. ^^ 첫번째 노드에 primary shard 가 모두 배치된 뒤 replica shard 들이 unassigned 상태에서 두 번째 노드가 start 되면서 배치되었다면 한쪽 노드에 primary shard 가 몰려있어서 어떤 룰이 있는 것처럼 느껴지실 수는 있지만, 노드를 하나 더 띄워보시면 primary shard 와 replica shard 는 서로 구분없이 뒤 섞여 있다는 것을 확인하실 수 있습니다. 다만, 하나의 primary shard 와 이 shard 의 replica shard (즉, 동일한 데이터를 가지고 있는) 는 절대로 같은 노드에 위치할 수 없습니다. ^^
3. Primary shard 와 master node 는 전혀 관계가 없다고 말씀드릴 수 있습니다. Primary shard 는 마스터 노드에 위치할 수도 있고, 그렇지 않을 수도 있습니다. 마스터 노드가 가지고 있는 메타정보는 검색시 보다는 오히려 인덱싱 과정에서 (또는 retreieve 과정) 문서의 id 값을 기준으로 해당 id 를 갖는 문서가 어떤 샤드에 인덱싱 되어야 하는지 (또는 해당 샤드가 어디에 있는지) 를 결정하는 역할을 합니다. 검색시에는 아무리 마스터 노드라고 해당 검색 결과가 어떤 노드에, 또는 어떤 샤드에 있는지 알 수가 없습니다. ^^
저도 좀 두서없이 답을 달아서… 도움이 되셨는지 잘 모르겠습니다. ^^
- 엘라스틱했어요~2015년 2월 3일 at 5:32 오전 - Reply
아 정말 많은 도움이 됬습니다.
shard와 replica와 관련해 한가지 질문이 더 있는데요.
제가 알기로 shard와 replica는 cluster구성 후 최초 index수행 후에는 변경이 불가능한 것으로 알고 있습니다.
1. 만약 shard : 5 , replica : 1로 설정되어 있는 cluster에 shard: 2, replica : 1과 같이 설정이 다른 새 노드가 동일한 cluster명으로 접근하게 된다면 어떤 현상이 발생하게 될나요? 실제로 수행하여 보니 별다른 문제 없이 replica가 새 노드에 재분할된 것처럼 보입니다.
2. 만약 cluster구성 후 elasticsearch로 서비스를 하다 불가피한 이유(막대한 양의 데이터 유입으로 인한 shard 증가 필요)로 이해 shard와 replica에 대한 cluster 설정을 변경해야 한다면 어떤 방법이 있을까요? 전체 full 색인으로 신규 index를 만드는 방법밖에는 없을까요?
답변 부탁드리겠습니다.
넵~
먼저, 1번에 대해서 간단히 설명을 드리도록 하겠습니다. ^^
먼저, shard 와 replica 의 개수는 클러스터의 기본값이 존재하기는 하지만 기본적으로 인덱스별로 각각 개별적인 값을 갖는다고 생각하시면 됩니다. 즉, A 라는 인덱스가 shard 5 개 replica 1로 구성되어 있다면, 그 이후에 노드가 추가되는 것은 해당 인덱스의 설정값에 전혀 영향을 주지 않습니다. 그리고 추가로… shard 의 개수는 한번 정해지면 인덱스를 다시 생성하지 않는 이상 변경이 불가능하지만, replica 의 개수는 실행시점에서도 언제든지 변경할 수 있습니다.
2. 만약, shard 의 개수를 늘려야하는 상황이 필요하다면 제가 아는 방법으로는 해당 인덱스를 다시 생성하는 방법밖에 없을 것 같습니다. 혹시 더 좋은 방법을 알게 되시면 저도 알려주시면 감사하겠습니다. ^^
- 엘라스틱했어요~2015년 2월 3일 at 6:58 오전 - Reply
계속 질문에 질문이 꼬리를 무는것 같아 죄송하네요 ㅠ.ㅠ
또 replica에 대해서 이해가 잘안되는 것이 있는데요.
위 포스팅 중 replica의 존재 이유인 “검색 성능”과 “장애복구”에서 두 번재 장애 복구에 대해서는 이해가 됬습니다.
(n개의 노드 이상 발생 시 최소 n+1개의 노드가 존재하며 최소 n-1개의 replica가 존재해야 정상적인 서비스가 유지된다는 점)
그런데 검색 성능에 관한 언급이 없으셔서요.
1. replica가 늘어날 수록 검색 시 검색 요청을 보내고 받아서 취합해야 할 shard가 늘어나게 되니 당연히 검색 성능이 떨어지게 되지 않나요?(elasticsearch는 특별한 라우터 기능을 사용하지 않는 한 모든 shard에 검색 요청을 하니깐)
2. 또한 replica개수 만큼 노드에 복사본이 만들어지게 되니 disk사용량도 급격히 올라갈 것으로 보이는데 이것과 관련해서
replica의 갯수를 제한을 두지는 않나요?(일반적으로 서비스 시 n+1개의 노드가 있다면 n-1개의 replica를 설정하진 않을것으로 보임)많이 배우고 있습니다. 감사합니다.
넵~ 답이 늦어서 죄송합니다. ^^
1. 먼저, replica 가 “검색 요청”은 인덱스를 구성하는 모든 샤드에 전달되는 것이 아니라, 인덱스를 구성하는 모든 “샤드셋”에 전달된다고 보시면 됩니다. 예를 들어 A 라는 인덱스를 구성하는 샤드가 주샤드 5개 (1, 2, 3, 4, 5) replica 1 (1′, 2′, 3′, 4′, 5′) 으로 굿성되어 있다면, 검색요청이 전달되는 샤드는 (1, 2′, 3, 4′, 5) 또는 (1′, 2′, 3, 4, 5′) 이렇게 주샤드와 복제샤드의 구분없이 전체 셋을 구성하는 샤드에 전달되기 때문에 replica 의 개수가 증가한다고 해서 취합해야하는 데이터의 양이 증가하지는 않습니다. ^^
2. 말씀하신대로 Replica의 수가 많아지면 디스크의 사용량이 늘어나게 됩니다. Replica 의 개수는 전체 노드 수와 샤드의 수, 그리고 어느정도의 fail over 를 기준으로 할 것인지 운영노하우에 따라서 결정을 하는데요… 이전 글에서 말씀드렸듯이 replica 의 개수는 실행시점에(on the fly) 변경이 가능하기 때문에 디스크 사용량과 장애율에 따라서 조절해 나가시는 것이 맞을 것 같습니다. ^^ 따로 정답이 있는 것은 아니지만 기본적으로 replica 의 수가 노드의 수와 같거나 많으면 불필요하게 unassigned 되는 샤드들이 발생하므로 노드의 수보다 작게 설정합니다. ^^
안녕하세요.
ElasticSearch 관련하여 테스트를 하고 있는데 궁금한게 있어 댓글 남깁니다.노드가 1개만 있는 상태에서 기본 세팅인 아래 수치로 설정하고 서버를 구성하였습니다.
index.number_of_shards: 5
index.number_of_replicas: 1여기서 인덱스를 새로 생성하게 되고 _cluster/state를 체크해보면 Unassigned로 된 node가 되어있고 클러스터 상태가 YELLOW로 되게 됩니다.
같은 노드내에 동일한 replica가 존재하면 안되기 때문인거 같은데요.
만약 정상적인 shard에 문제가 생기면 Unassigned에 있는 shard가 활성화가 되는건가요?
아니면 replica를 사용하기 위해서는 반드시 2개 이상의 node가 필요한건가요?질문이 두서가 없네요. 양해 부탁 드립니다.
안녕하세요. 질문 주셔서 감사합니다. ^^
먼저, node 가 하나인 경우 동일한 primary shard 와 replica shard 는 같은 노드에 존재할 수 없기 때문에 unassigned shard 가 존재하게 됩니다.
이러한 상황에서 primary shard 에 문제가 생기면 replica shard 가 그자리를 대체하는 것이 아니라, 해당 shard 가 가지고 있던 데이터를 조회할 수 없게 됩니다.
데이터의 유실방지를 위해서 replica 수를 1로 하는 경우 반드시 두 개 이상의 노드가 필요합니다. ^^
감사합니다. ^^
- janghoon2015년 8월 17일 at 11:22 오전 - Reply
안녕하세요
엘라스틱서치에 대해 많은 궁금증을 해결해주셔서 감사합니다.
감사하다는 인사와 함께 여쭤볼게 있어 이렇게 글을 남기게 되었습니다.그저 그런 초보 프로그래머가 엘라스틱서치를 개발하게 되어 여러가지 어려움이 많네요ㅠㅠ
바로 질문 드릴게요첫째로 클라이언트 노드에 필요성을 느끼지 못해(여기의 글을 보기 전) 3개의 장비를
1. master true data true 2. master true data true 3. master false data true 로 설정하고 매번 마스터 노드에만 요청을 하고 있었습니다.
이 상태에서 클라이언트 노드를 설정하고 싶다면 위에서 답변주신 것처럼 장비를
1. master false data false 2. master true data true 3. master true data true 로 설정하고 클라이언트 노드에 요청을 해야겠지요.
그런데 제가 하고 싶은거는 현재 1번 노드를 클라이언트로 노드로 바꿀때 기존의 데이터들을(현재 Unassigned) 어떻게하면 나머지 두 데이터 true노드들로 분배할 수 있을까요?둘째로 sort와 aggregation의 문제로 질문 드리겠습니다.
제가 이해한 바로는 sort와 aggregation 은 field data를 생성하기 때문에 많은 량은 메모리를 사용한다고 알고 있습니다. 그리고 무엇보다 느리고요.
1. 제가 원하는 바 두가지가 있습니다.
하나는 제가 요청하는 쿼리의 검색 결과만을 가져와 그 결과만을 소팅하거나 aggregation 작업을 했으면 하는데 자료를 찾아봐도 우선 field data를 생성하고 쿼리를 수행하는 것 같았습니다.
2. sort와 aggregation을 요청하게 되면 지나치게 느려집니다. 한 번의 요청을 900초가 걸려 수행해낸다던지 물론 이 질문을 하기 위해 저의 설정을 보여드려야 하겠지요
요청하시면 설정, 장비 스펙, 쿼리까지 다 보여드리겠습니다..ㅠㅠ너무 바보같고 부족한 질문에도 답변을 주신다면 감사하겠습니다..
안녕하세요. 질문 주셔서 감사합니다. ^^
1. 우선, 클라이언트 노드는 다음과 같은 이유로 필요합니다. ^^ 실제 클라이언트 노드 없이 aggregation 등을 수행하시다보면, 데이터를 가지는 노드가 자신의 shard 들에 대한 aggregation과 전체 결과를 합치는 역할을 동시에 수행하면서 성능은 물론, heap memory의 out of memory 발생이 빈번히 발생하시게 될 겁니다. 이러한 이유로 결국 로드 밸런싱 역할만을 수행하는 클라이언트 노드가 필요하게 됩니다. ^^ 특정 노드를 클라이언트 노드로 설정하시려면
node.client: true를 설정해 주시면 됩니다. 노드의 설정이 변경된 뒤 해당 노드를 재실행 해주시면 자동적으로 샤드들이 재분배(relocating)됩니다. 만약, 그럼에도 불구하고, unassigned shard 가 존재한다면,(replica의 수 + 1) < = node.data: true인 노드의 수인지 한번 확인해봐 주시면 좋을 것 같습니다. ^^2. 우선 aggregation의 경우, 기본적으로 query 결과에 대해서만 수행하게 됩니다. 그렇기 때문에, 수행시간이 너무 오래 걸린다면, aggregation 자체를 한번 봐야할 것 같습니다. ^^
Sort의 경우에는 query 결과에 대해서만 정렬을 수행하기 위한 방법은 잘 모르겠습니다만, 성능 등의 이슈가 있다면 필드의 데이터 유형이 문자열인 경우, 해당 필드의 데이터가 analyze 되지 않는not_analyzed필드를 만들어서 해당 필드에 대하여 정렬을 수행하시는 것이 바람직합니다.답변이 부족할 수도 있는데, 혹시 더 필요하신 내용이 있으시면 말씀해주시면 감사하겠습니다. ^^
- janghoon2015년 8월 17일 at 6:45 오후 - Reply
분에 넘치는 빠른 답변을 받아 행복합니다 ㅎㅎ
답변 주셔서 감사합니다.(replica의 수 + 1) < = node.data: true 라고 하셨는데 실제로 저에게는 replica가 필요가 없어 replica는 0입니다. 프라이머리 샤드만을 사용하고 있습니다.
그런데도 unassigned shard 로 되어 재분배가 일어나지 않고 있습니다..ㅠㅠ
일단 제가 설정한 부분을 보여드려야 할 것 같아서 보여 드리겠습니다.
부족한 영어실력에 혼자 이리지리 돌아다니면서 검색하다보니 엉망진창입니다.
/config/elasticsearch.yml
개별
1. node.master: false node.data: false 2. node.master: true node.data: true 3. node.master: true node.data: true
공통
index.number_of_shards: 35
index.number_of_replicas: 0
index.cache.field.type: softindices.breaker.fielddata.limit: 85%
indices.breaker.total.limit: 85%
indices.fielddata.cache.size: 75%
indices.breaker.request.limit: 55%
indices.memory.index_buffer_size: 10%cluster.routing.allocation.disk.threshold_enabled : false
cluster.routing.allocation.balance.shard: 0.1
cluster.routing.allocation.balance.index: 0.9
#discovery.zen.minimum_master_nodes: 1
공통
/bin/elasticsearch
export ES_HEAP_SIZE=16g이렇게 되어있습니다..너무 엉망이라 창피한데 다음에는 안 창피하려고 여쭤봅니다
엉망이라뇨~ ^^; 저도 어차피 같이 배워나가는 사람일 뿐입니다. ^^
말씀하신 내용만 보면, shard relocation이 정상적으로 이루어져야 하는데, 현재 제가 아는 지식으로는 원인을 잘 모르겠네요. ^^;저도 종종 알 수 없는 원인으로 unassigned shard 가 relocating 되지 않는 경우에는 아래와 같은 방식으로 강제 reroute를 하고는 하는데요, 매번 이렇게 하는 게 맞는 건지는 잘 모르겠네요. ^^
curl -XGET http://localhost:9200/_cat/shards | grep UNASSIGNED | awk '{print $1,$2}'curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands" : [ {
"allocate" : {
"index" : "your_index_name", < -- 인덱스 명 "shard" : 4, <-- shard 번호 "node" : "your_node_name", <-- 노드 명 "allow_primary" : true } } ] }'혹시, 이 내용이 원하시는 답변이 아니시라면, (그리고 혹시 페이스북을 하신다면) 아래의 페이스북 그룹에 가입하시고 다시 질문을 한번 올려 보시겠어요? ^^ 좋은 분들이 많아서 혹시 원하시는 답을 얻으실 수도 있을 것 같습니다. ^^
https://www.facebook.com/groups/elasticsearch.kr/
- janghoon2015년 8월 25일 at 1:09 오후 - Reply
답변을 빠르게 주셨는데 제가 출장 후 휴가가 바로 있어서 글을 확인하지 못했네요.
매번 빠른 답변에 감사드립니다.샤드의 재분배에 관한 부분은 말씀대로 진했했습니다.
다른 설정의 변경없이 클라이언트 노드의 생성만으로도 성능이 엄청나게 향상되었습니다. 감사합니다.지난번에 제 쿼리에 대해 답변을 주셨는데 그 때도 출장준비 중이었거든요 ㅠㅠ
1. 우선 sort에 관한 쿼리는
{
“query”: {
“filtered”: {
“filter”: {
“bool”: {
“must”: [
{
“range”: {
“date”: {
“from”: “2015/06/01 00:00:00″,
“to”: “2015/06/30 23:59:59″
}
}
}
],
“must_not”: [],
“should”: []
}
}
}
},
“sort”: [
{
“date”: {
“reverse”: true
}
}
],
“aggs”: {}
}
이런 방법으로 보내고 있으며 전체 인덱스에 쿼리를 날리지 않고 월별로 나누어진 인덱스에 쿼리를 보내고 있습니다.
인덱스는 평균적으로 docs: 4,502,021,488 size: 568Gi 이정도가 됩니다.2. aggregation에 관한 쿼리는
{
“query”: {
“filtered”: {
“filter”: {
“bool”: {
“must”: [
{
“range”: {
“date”: {
“from”: “2015/06/01 00:00:00″,
“to”: “2015/06/30 23:55:00″
}
}
},
{
“range”: {
“test_alpha”: {
“from”: “aaa”,
“to”: “zzz”
}
}
}
],
“must_not”: [],
“should”: []
}
}
}
},
“sort”: [],
“size”: 0,
“aggs”: {
“test_aggs”: {
“terms”: {
“field”: “test_alpha”,
“size”: 100,
“order”: {
“inA.sum”: “desc”
}
},
“aggs”: {
“inA”: {
“stats”: {
“field”: “in_a”
}
},
“outA”: {
“stats”: {
“field”: “out_a”
}
},
“inG”: {
“stats”: {
“field”: “in_g”
}
},
“outG”: {
“stats”: {
“field”: “out_g”
}
}
}
}
}
}
현재는 sort는 client 노드를 설정하므로 성능이 향상이 되었는데 aggregation 의 성능은 많이 뒤쳐지고 있습니다.
1100초가 넘게 걸리기도 하고 그러네요 ㅠㅠ3. 저는 현재 월별로 나누어진 인덱스에 쿼리를 보내 응답을 기다리고 있습니다. sort와 aggregation 모두 말이죠.
요청을 주소로만 보내는 것보다 주소뒤에 인덱스를 설정해주는 것이 훨씬 성능이 좋은것 같아서 이렇게 하고 있습니다.
제가 드는 의문은 제가 took시간에 인덱스를 지정하는 것은 크게 효과가 나타나지만 _type을 지정하여 쿼리를 보내는 부분에서는 크게 효과가 나타나지 않았습니다.
혹시 _type에는 인덱스와는 다른 개념으로 받아드려야 하는것인가요?매번 명쾌한 답변을 주셔서 감사합니다.
여기 페이스북은 전에 가입하려 했는데 가입승인이 안나서 질문을 못올렸었어요 지금 다시 신청해볼게요 ㅎㅎ
앗. 덧글을 주신지 오래 되었는데 제가 미처 확인을 못했네요… ㅜㅜ
실제 데이터를 넣어보고 테스트를 해보면 좋을 것 같은데, 제가 최근에 여유가 없어서 좀 어려울 것 같습니다.
저번에 말씀드린 것 처럼 facebook 그룹에 aggregation 을 올려보시고 다른 분들께 개선 사항이 없는지 여쭤보시는 것도 빠른 방법일 것 같습니다. ^^제대로 된 답변 드리지 못해서 죄송합니다. ^^;
안녕하세요~
검색을 통해 들어오게 됐는데 덕분에 많이 배웠습니다^^저는 얼마전에야 비로소 ELK 셋팅을 해봤는데요.
WAS 10 대의 로그를 logstash 를 이용해서 ES에 넣고 있습니다.
시험삼아 해 본 것이라 현재는 ES 노드를 하나만 운용하고 있는데요,
향후 확장성을 고려해서 클라이언트 – Data 노드(2) 구성으로 클러스터링을 하려고 합니다.
이와 관련해서 궁굼한 점이 있는데요,
현재 운영중인 ES서버를 클라이언트로 셋팅 하고 데이터 노드 2대를 구성하면 기존에 만들어졌던 데이터들은 새로 구성한 데이터 노드 2대에 자동으로 이전이 되나요?네. 그렇습니다. ^^
좀 더 안전하게 처리하기 위해서는 기존의 노드를 그대로 둔 채, 데이터 노드를 추가하고 샤드가 relocate 완료되면 그 때 기존 노드를 client 로 설정하면 더욱 좋을 것 같습니다. ^^
감사합니다.이렇게 빨리 답변을 주시다니, 감사합니다 ^^
그런데 상황이 좀 바뀌어서 하나 더 질문을 드려봅니다.
원래 계획은 기존에 쓰던 서버를 클라이언트로 바꾸고 데이터 노드를 추가하는 것 이었는데 사정상 다른 공간에 있는 서버로 변경이 필요하게 되었습니다. 그래서 불가피 하게 데이터를 통째로 다른 서버로 옮기는 작업을 해야 하는데 이 때도 ES의 클러스터링을 이용할 수 있을지 궁굼합니다.
즉, 현재 구조인 ZONE1/ES-OLD 에 ZONE2/ES-DATA-NODE1, ES-DATA-NODE2, ES-NEW-CLIENT(node.data:false, node.master:false) 를 추가하고 relocate가 완료되면 ES-OLD를 빼면 될까요?만약 Zone1 의 노드와 Zone2의 노드가 public IP를 이용해서 통신이 가능하다면 unicast 를 이용해서 클러스터를 구성할 수도 있습니다. 하지만 이러한 방식 보다는 snapshot/restore 를 이용해서 데이터를 옮기시는 것이 더 수월할 것 같습니다. ^^ (https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-snapshots.html)
안녕하세요.
엘라스틱 고수분인듯보이내요^^다름이 아니오라 제가현재 6대 was에 같은서버에 엘라스틱을 구상해놨는데 20여일 잘쓰다가 갑자기 out of memory를 만나게 됐습니다.. 이유를 잘 몰라서 그러는데 indexing 도중에는 문제가 없고 검색시 현재 문제가 발생 하더군요 검색은 aggregation, post filter, sorting, search 이4가지 조합으로 검색을합니다.
현재 엘라스틱 메모리는 1g 디폴트로 구성되어있습니다. 이유가 먼지 알려주시면 고맙습니다 ㅠㅠ
두서없이 글쓴거 같어 죄송하네요
혹시 yml설정이 문제이면 다시 올려 드리겠습니다안녕하세요. ^^ 제가 고수는 아니지만 최대한 아는대로 답변을 적어 드리겠습니다.
검색에서 메모리가 부족한 경우 대부분 aggregation으로 인한 경우가 많습니다. 최초 요청을 받은 노드는 다른 샤드의 결과들을 취합하여야 하기 때문에 별도의 작업을 추가로 해야하는데요, 만약, 클라이언트 노드를 별로로 두지 않으셨다면 결과를 취합하는 노드의 경우 본인이 가지고 있는 샤드의 aggregation 과 함께 전체 결과를 취합해야 하기 때문에 메모리가 부족할 가능성이 높습니다.
데이터를 가지고 있지 않고 마스터로도 사용되지 않는 클라이언트 노드를 하나 두시고 해당 노드로 요청을 해보시면 좋을 것 같습니다. ^^답변 고맙습니다. “Hosang Jeon” 님 말씀대로 그렇다면 먼저 yml에서 노드 한대는 master: false, data : false로 하고 aggregation의 경우 이 노드로 요청을 하라는 말이 맞지요? ^_________^
후 그 이유 라면 좋겠네요 ㅠㅠ 두다리 뻗고 자고 싶네요..
아 그리고 한개더 질문 드릴께요 … ㅡㅡ;
index.cache.field.type: softindices.breaker.fielddata.limit: 85%
indices.breaker.total.limit: 85%
indices.fielddata.cache.size: 75%
indices.breaker.request.limit: 55%
indices.memory.index_buffer_size: 10%
이 셋팅이 아마도 query cache 관련 인듯 보이는데 설정은 윗분꺼 참조 했습니다.
이런식으로 셋팅 하면settings을 설정 할때
curl -XPUT localhost:9200/my_index -d’
{
“settings”: {
“index.cache.query.enable”: true
}
}
위 curl도 필요 한지요…
그럼 말씀 기다리겠습니다. ㅠㅠ
'ElasticSearch > 외부자료' 카테고리의 다른 글
| [외부] Elasticsearch 인덱싱 최적화 (0) | 2018.04.17 |
|---|---|
| [외부] Elasticsearch Configuration (0) | 2018.04.13 |
| [외부] ElasticSearch: Enable Mlockall in CentOS 7 (0) | 2018.04.13 |
| [외부] Elasticsearch로 로그 수집하기, 실전! (0) | 2018.04.12 |
| [외부] Rolling Restarts [클러스터(또는 노드) 재시작하기] (0) | 2018.04.05 |